
예기치 못한 서비스 장애가 발생했을 때, 여러분의 팀은 얼마나 빠르게 대응할 수 있나요? 장애 발생부터 복구까지 이어지는 과정을 체계적으로 관리하지 못하면 단순한 기술 문제가 고객 신뢰 저하로 이어질 수 있습니다. 'Jira Service Management(JSM)'는 인시던트 감지부터 사후 검토까지 전 과정을 하나의 플랫폼에서 일관되게 처리할 수 있도록 지원합니다. 이번 콘텐츠에서는 인시던트 관리의 핵심 프로세스와 JSM의 실무 활용법을 단계별로 살펴보겠습니다.
1. 인시던트 관리(Incident Management)란 무엇인가요?
'인시던트 관리(Incident Management)'는 예기치 않은 이벤트나 서비스 중단 발생했을 때, 신속하게 대응해 서비스를 정상 운영 상태로 복구하는 IT 프로세스입니다. 체계적인 인시던트 관리 체계가 없다면 장애 대응 과정은 담당자 개인의 역량과 경험에 의존하게 됩니다. 그 결과 대응 속도와 품질이 일정하지 않고, 같은 장애가 반복되는 악순환에 빠지기 쉽습니다. 먼저 자주 헷갈리는 용어부터 짚어보겠습니다.
✔️인시던트(Incident): 예기치 않은 서비스 중단 또는 서비스 품질 저하를 의미합니다.
✔️주요 인시던트(Major Incident): 비즈니스에 중대한 영향을 미치며, 즉각적이고 조율된 대응이 필요한 심각한 인시던트입니다.
✔️문제(Problem): 하나 이상의 인시던트를 발생시킨 아직 알려지지 않은 근본 원인을 의미합니다.
2. 왜 JSM으로 인시던트를 관리해야 할까요?
수많은 ITSM 솔루션 중에서도 JSM이 글로벌 기업의 표준으로 자리 잡은 데에는 분명한 이유가 있습니다.
✔️개발-운영 사일로의 통합
JSM은 Jira Software와 동일한 플랫폼 위에서 동작합니다. 따라서 장애 발생 시 의심되는 배포 및 코드 커밋 이력을 바로 추적할 수 있습니다. 운영팀이 개발팀에 '어떤 배포가 나갔는지'를 따로 확인하는 시간을 줄일 수 있습니다.
✔️ChatOps 기반 실시간 협업
Slack 또는 Teams 채널을 티켓에서 직접 생성하고, 화상 회의까지 한 화면에서 시작할 수 있습니다. 이를 통해 MTTA(평균 응답 시간)와 MTTR(평균 복구 시간)을 함께 단축할 수 있습니다.
✔️Opsgenie의 검증된 알림 & 온콜 기능 내장
2018년 아틀라시안이 인수한 글로벌 인시던트 관리 솔루션 Opsgenie의 알림·온콜 기능이 현재 JSM에 네이티브로 통합되어 있습니다. Opsgenie 단독 제품은 2025년 6월 신규 판매가 중단되었고, 2027년 4월 서비스 종료가 예정되어 있습니다. 이에 따라 JSM 중심의 통합 운영이 사실상 표준 흐름으로 자리 잡고 있습니다.
✔️Confluence 연동 기반 지식 자산화
장애 사후 분석 문서를 Confluence에 축적할 수 있어, 시간이 지날수록 팀의 대응 역량이 강화되는 선순환 구조를 만들 수 있습니다.
3. 인시던트 대응 프로세스 6단계
인시던트 상태는 크게 [NEW → FIXING → RESOLVED] 단계로 나눌 수 있습니다. 각 상태 전환 사이에서는 다음과 같은 핵심 활동들이 체계적으로 진행됩니다.

[출처=Atlassian]
1️⃣인시던트 감지: 모니터링·알림 도구 또는 고객 신고를 통해 장애를 최초 인지합니다.
2️⃣팀 커뮤니케이션 채널 설정: Slack·Teams 채널을 즉시 구성해 대응팀의 단일 소통 창구를 확보합니다.
3️⃣영향 평가 및 심각도 분류: 영향받는 고객 수, 연관 이슈, SLA 임박 여부를 기준으로 인시던트의 우선순위를 결정합니다.
4️⃣이해관계자 커뮤니케이션: 내·외부 관계자에게 신속하고 정확하게 현황을 공유해 신뢰를 유지합니다.
5️⃣에스컬레이션 및 역할 위임: 1차 대응자는 필요 시 추가 팀원을 호출하고, 각 담당자에게 역할을 분담합니다.
6️⃣인시던트 해결 및 사후 전환: 긴급 대응이 마무리되면 정리 작업과 PIR 단계로 자연스럽게 전환됩니다.
4. JSM 인시던트 관리 핵심 기능 살펴보기
JSM은 위의 6단계 워크플로우를 하나의 티켓 화면 안에서 처리할 수 있도록 설계되어 있습니다. 실무에서 자주 활용되는 기능을 순서대로 살펴보겠습니다.
① 초기 설정 및 담당자 지정
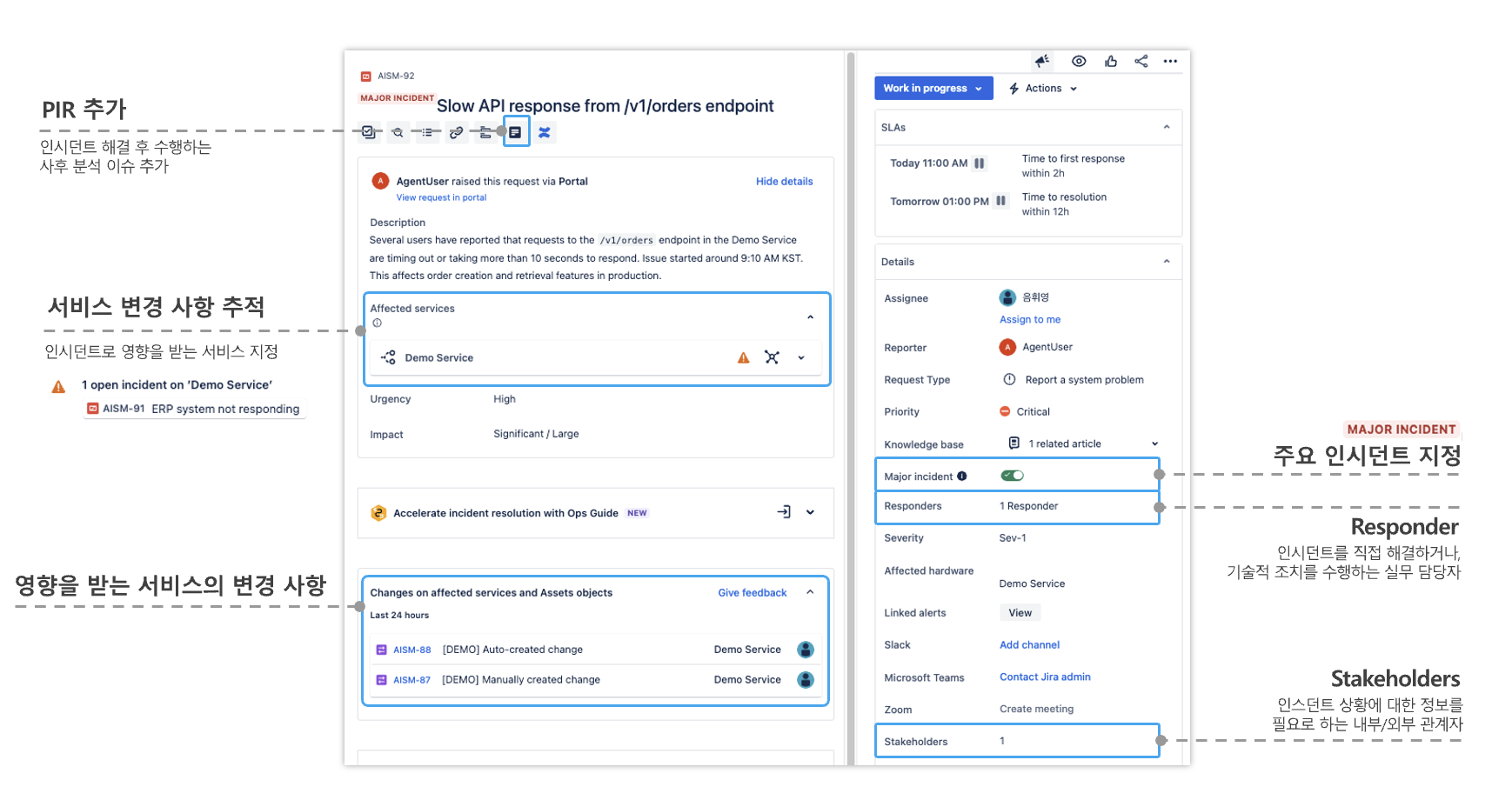
[출처=플래티어]
인시던트 티켓을 열면 가장 먼저 아래 항목을 설정합니다.
✔️Major Incident 지정: 비즈니스 영향도가 큰 장애라면 우측 패널의 Major Incident 토글을 활성화해 최우선 처리 대상으로 분류합니다.
✔️Responder 할당: 기술적 조치를 직접 수행할 실무 담당자를(ex. 엔지니어, 개발자 등) 지정합니다.
✔️Stakeholders 추가: 직접 조치에는 참여하지 않지만 진행 상황을 반드시 공유받아야 하는 유관부서 리더나 경영진을 등록합니다.
② 영향 범위 파악 (Affected Services)
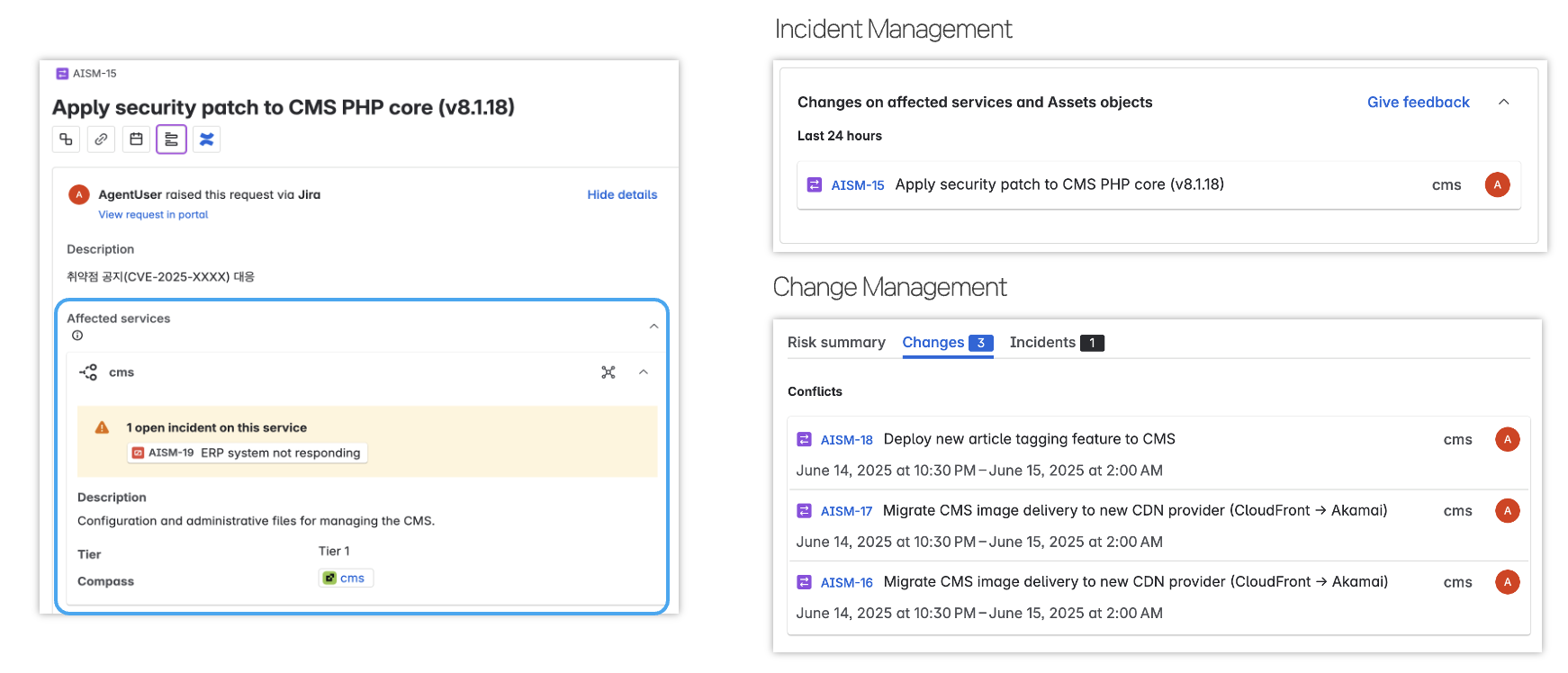
[출처=플래티어]
티켓의 'Affected Services' 항목에 장애 영향을 받는 시스템을(ex. 결제·ERP 등) 지정하면 해당 서비스와 연관된 오픈 인시던트 및 변경 작업 내역이 자동으로 표시됩니다.
이를 통해 장애 범위를 한눈에 파악하고, 관련 변경 작업이 원인일 가능성도 빠르게 검토할 수 있습니다.
③ 실시간 협업 (Slack & 전화 회의 연동)

[출처=플래티어]
✔️전용 Slack 채널 생성: 티켓 안에서 바로 채널을 생성해 대응자를 초대할 수 있습니다. 모든 논의는 티켓 활동 로그에 자동으로 동기화됩니다.
✔️전화 회의(Conference Call): 비디오·오디오 회의를 티켓에서 즉시 시작해 중앙 집중식으로 상황을 통제할 수 있습니다.
④ 시스템 원인 조사 (Investigate)
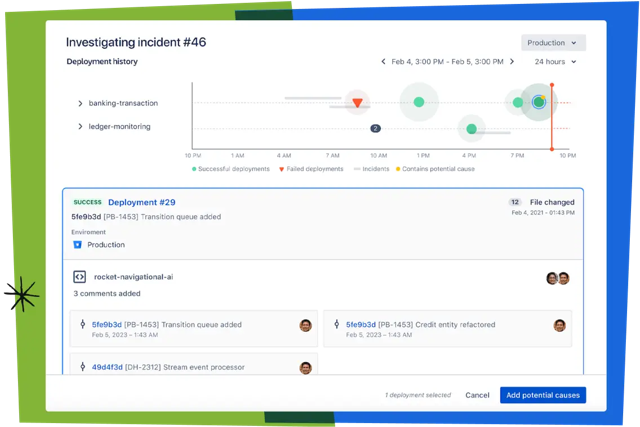
[출처=Atlassian]
[Investigate] 패널에서는 장애 발생 전후의 시스템 변경 이력을 타임라인으로 확인할 수 있습니다.
최근 배포 내역이나 코드 커밋 이력을 분석해 원인으로 의심되는 항목을 [Select as potential cause]로 표시하면 사후 검토 단계까지 추적성을 유지할 수 있습니다.
⑤ 플레이북(Playbook) 실행
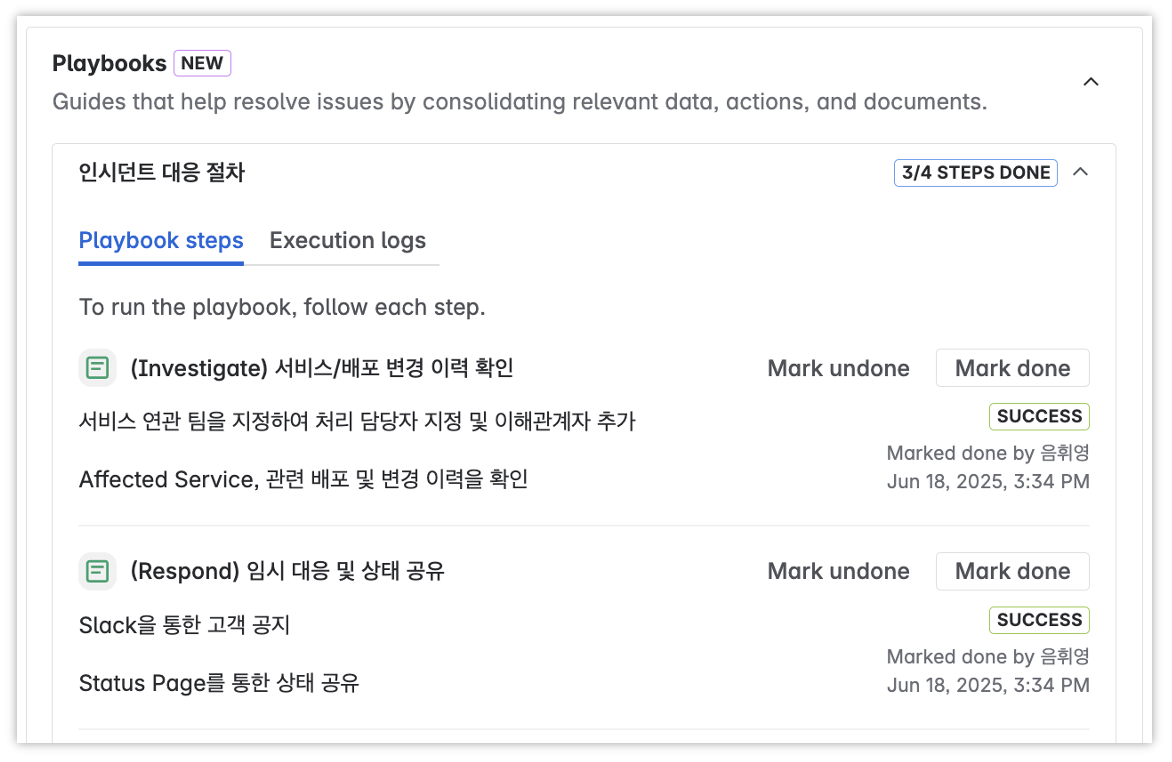
[출처=플래티어]
장애 유형별로 사전에 정의된 표준 대응 절차를 실행해 누락 없이 일관된 조치를 수행할 수 있습니다.
✔️[Investigate], [Respond], [Recover] 각 단계별 가이드를 따라 대응을 진행합니다.
✔️Slack 공지, Statuspage 상태 업데이트 등 반복 작업은 Run 버튼 클릭으로 자동화할 수 있습니다.
✔️각 단계 완료 후에는 [Mark done]을 클릭해 실행 로그를 남깁니다.
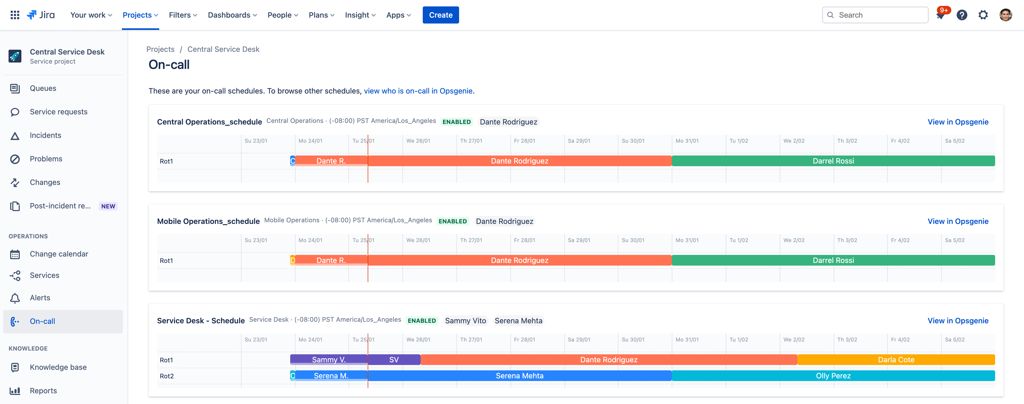
⑥ 온콜 및 알림 통제 (Operations)
JSM의 Operations 영역은 아틀라시안이 인수한 Opsgenie의 알림·온콜 엔진이 통합된 기능입니다.
다년간 글로벌 기업의 인시던트 대응을 지원해 온 검증된 역량을 제공합니다.
[출처=Atlassian]
✔️다양한 모니터링 툴 연동: Datadog, AWS CloudWatch, Prometheus 등 200여 종 이상의 모니터링 툴 알림을 JSM으로 인입할 수 있습니다.
✔️자동 알림 라우팅: 사전 설정된 온콜 스케줄과 라우팅 규칙에 따라 담당자에게 자동으로 알림이 발송됩니다.
✔️다채널 알림: 이메일, 모바일 푸시, SMS, 음성 전화까지 지원해 알림 누락을 방지합니다.
✔️자동 에스컬레이션: 1차 담당자가 응답하지 않으면 사전 정의된 정책에 따라 다음 담당자에게 자동으로 호출됩니다. 이를 통해 MTTA(평균 응답 시간)를 크게 단축할 수 있습니다.
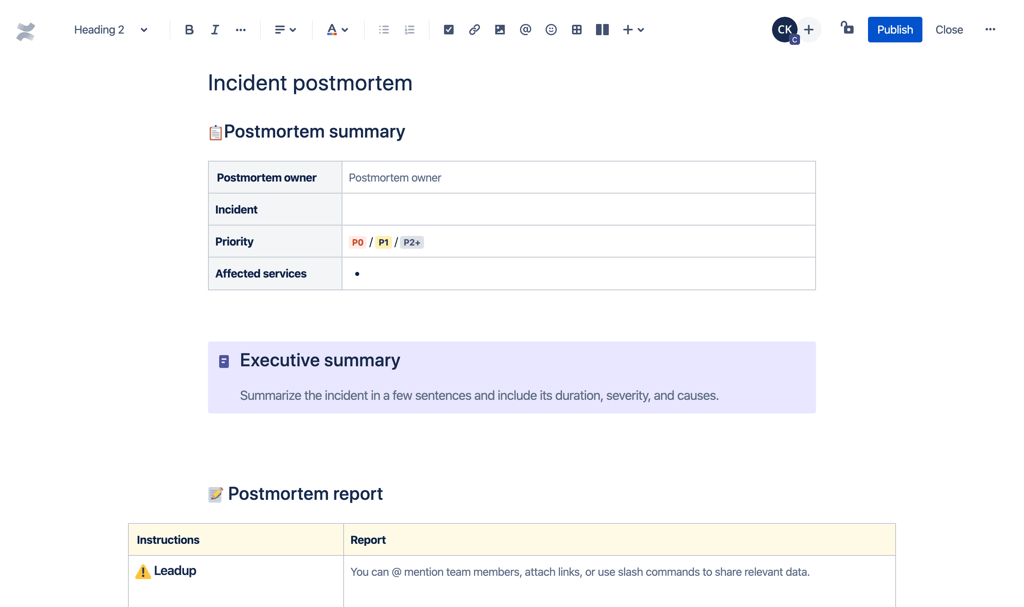
5. 장애 후 반드시 챙겨야 할 것, PIR(Post-Incident Review)
[출처=Atlassian]
장애를 복구했다고 해서 모든 과정이 끝나는 것은 아닙니다. 동일한 장애가 반복되지 않으려면 근본 원인을 규명하고, 재발 방지 대책을 수립하는 PIR(사후 검토) 과정이 반드시 필요합니다. JSM은 Confluence와 연동해 이 과정을 자연스럽게 이어갈 수 있도록 지원합니다.
| 단계 |
주요 활동 |
| PIR 이슈 생성 |
장애 티켓 종료 후, Post-Incident Review 유형의 이슈를 생성하고 원본 티켓과 연결 |
| Postmortem 문서 자동 생성 |
PIR 티켓 내 [Create postmortem] 클릭 → Confluence에 분석 문서 자동 생성 |
| 분석 및 문서화 |
타임라인 정리, 5 Whys 기법으로 근본 원인 도출, 재발 방지 액션 아이템 수립 |
| 리뷰 및 지식 자산화 |
RCA 미팅 진행 후, 완성된 문서를 팀 지식 기반(KB)으로 활용 |
특히 5 Whys 분석 기법은 '왜 장애가 발생했는가?'를 반복해서 물으며, 표면적인 증상이 아닌 실제 근본 원인을 찾아내는 방법입니다.
PIR의 과정에서 문제의 원인을 구조적으로 파악하는 데 유용하게 활용됩니다.
체계적인 인시던트 관리는 단순히 장애를 빠르게 해결하는 데서 그치지 않습니다. 매 장애를 통해 팀이 더 강해지는 선순환 구조를 만드는 과정입니다. JSM은 감지부터 사후 검토까지 전 과정을 하나의 플랫폼에서 일관되게 지원하며, IT 운영팀의 대응 수준을 한 단계 높여줍니다.
플래티어는 Atlassian 공식 파트너로서 다양한 기업의 ITSM 도입 및 프로세스 구축을 직접 지원해 왔습니다. JSM 도입이나 인시던트 관리 체계 개선을 고민하고 있다면, 플래티어의 전문 컨설팅을 통해 조직에 맞는 운영 체계를 함께 설계해 보시기 바랍니다.
